


Telex : xAI en passe de lever 6 Md$, Google et Microsoft forts dans le cloud et l'IA, Gravelines cyberattaqué
OpenAI ajoute des fonctions de sécurité, de contrôle pour les entreprises

Avec FlashSystem 5300, IBM muscle son stockage entrée de gamme
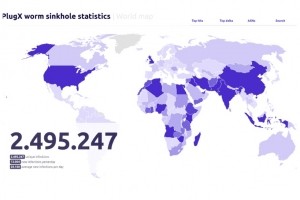
Le vieux malware PlugX continue d'infecter des millions de PC
OpenELM, un SLM open source signé Apple

Décryptage du DSI français et européen type

Backmarket bascule son cloud AWS chez Google Cloud

L'école 89 ouvre un bachelor en cybersécurité à Ferrières-en-Brie

Pour se renforcer sur les TPE-PME, Cegid va acquérir EBP

Orange Business débute 2024 avec une croissance atone
Sondage
-
Hier
- 17:48 Telex : xAI en passe de lever 6 Md$, Google et Microsoft forts dans le cloud et l'IA, Gravelines cyberattaqué
- 17:18 Darktrace racheté par Thoma Bravo pour 5,3 Md$
- 15:56 OpenAI ajoute des fonctions de sécurité, de contrôle pour les entreprises
- 15:33 Des débuts prometteurs pour l'IPO de Rubrik
- 14:41 Avec FlashSystem 5300, IBM muscle son stockage entrée de gamme
- 13:48 Le vieux malware PlugX continue d'infecter des millions de PC
- 11:54 OpenELM, un SLM open source signé Apple
- 11:32 Décryptage du DSI français et européen type
- 11:07 Backmarket bascule son cloud AWS chez Google Cloud
- 11:07 L'école 89 ouvre un bachelor en cybersécurité à Ferrières-en-Brie
- 08:44 Pour se renforcer sur les TPE-PME, Cegid va acquérir EBP
- 08:43 Orange Business débute 2024 avec une croissance atone
- 08:43 Savencia peaufine ses données consolidées avec le MDM de Semarchy
- 08:43 ChatGPT détrône Linkedin en tête du Shadow IT
- Lire toute l'actualité
















Derniers commentaires
"Sans compter sur le fait que les services des chambres consulaires en ont profité pour monnayer toute intervention qui a pour objet de rectifier un dysfonctionnement de la plate-forme, voire même,..."
par Visiteur, Guichet unique: les germes d'un fiasco scrutés par la Cour des comptes
"Email de France Travail reçu le 4 avril dans mes spams ..."
par Visiteur, Piratage de France Travail : aux origines du mal
"Merci beaucoup! J'AI énormément apprécié vos arguments au sujet de l'impact de la robotisation des entreprises sur l'emploi.Je suis moi-même un fan de la robotique et de l'intelligence artificielle,..."
par Visiteur, Intelligence artificielle : Les robots vont-ils détruire nos emplois ?